
不久前,我系毕业的博士生约瑟夫·斯蒂尔(JosephSteering)做了一个超级可爱的论文。
为了研究如何使社交媒体上的用户们相对文明地讨论极具争议性的政治议题,他和合作者们设计出了一系列不按常理出牌的验证码(Captcha)。跟普通的验证码(譬如,请找出下列带有汽车的图片)不同,斯蒂尔们设计的验证码们含有隐藏的心理学暗示,分为“积极”和“消极”两类。譬如,同样是请找出下列图片里带有人的那一组,“积极”的验证码里显示的图片大多是趋向乐观平静的(比如足球赛和音乐会),“消极”的验证码显示的图片却大多是令人不安的(比如醉酒者或是抑郁者)。
为了更好地测试不同类型的验证码对社交媒体用户发言的影响,在斯蒂尔的实验里,用户在发帖前,会被随机地分为两组,只有通过所属类别的验证码之后才能发帖。
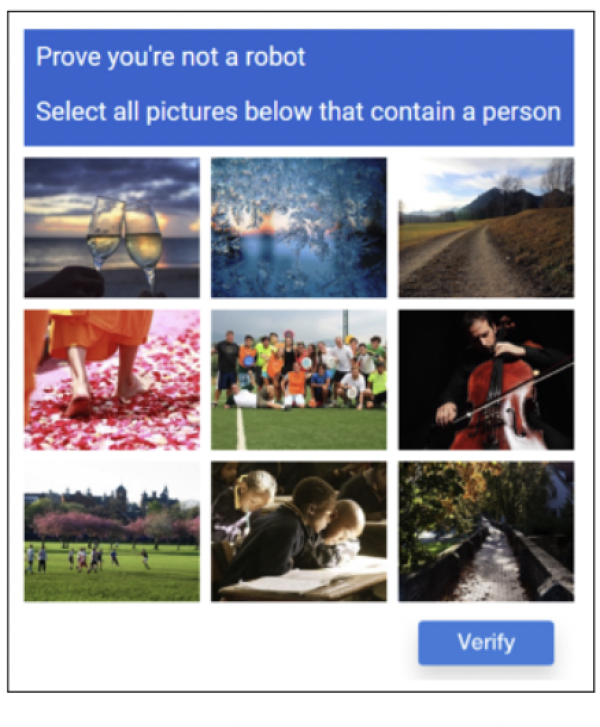
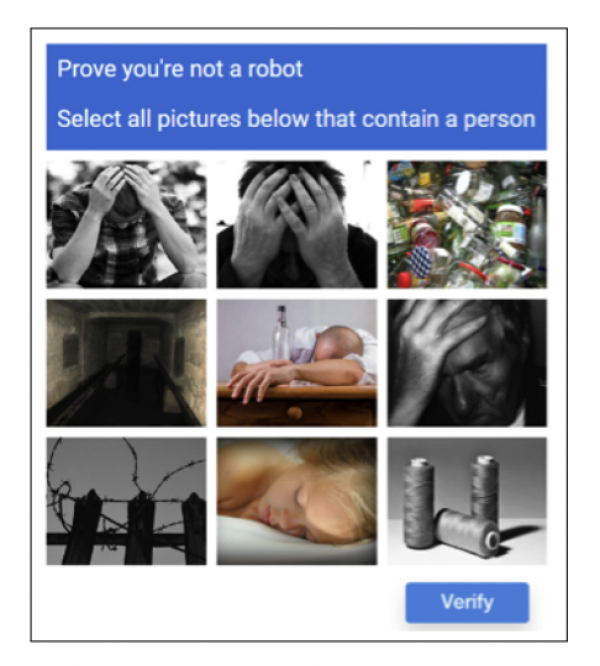
图为斯蒂尔实验里设计的两组验证码:上图是“积极的”;下图是“消极的”。来源:Seering,J.,Fang,T.,Damasco,L.,Chen,M.C.,Sun,L.,sBehaviourModel),就立志于在动机、能力和触发点这三个基本元素里寻找平衡。因为任何一个人类行为的发生,都需要满足以上三大基本元素:人们需要有产生行为的动机、要有实行行为的能力,以及正好有一个合适的触发点。
又比如,我们之前讨论过的“损失厌恶”(LossAversion),是指在面对同样数量的收益和损失时,人类会主观地认为损失比收益更加令他们难以忍受。譬如,与其告诉员工们“在繁忙的周五晚上工作会将你的收入提高25%”,还不如简单地更换一下语言的组织方式,告诉他们:“如果你不在周五晚上工作,你会比那些在周五晚上工作的少赚25%”。即使是一样的25%,告诉员工们“少赚”往往比“多赚”更能使他们愤懑难当。
再比如,人类还有非常严重的“确认偏差”(ConfirmationBias)。当我们确认一个观点之后,就会去竭尽全力地寻找证据来支持我们已经相信的观点,哪怕这一观点本身缺乏足够证据。我们会把模糊论据、疑似证据,不靠谱的消息、乃至假消息当成支持自己这一派的理由。有些时候,我们甚至会选择性忽略对自己观点不利的证据——不管那些证据是如何雄辩有力。
在社交媒体的进化史上,利用心理学原理进行设计的例子更是比比皆是,且大多以资本的利益为导向,以民众的智识为牺牲。今年五月,美国著名的社会心理学家、纽约大学商学院的教授乔纳森·海特(JonathanHaidt)在《大西洋月刊》(TheAtlantic)上发表了轰动一时的长文“为什么过去十年美国人的生活尤其愚蠢”(WhyThePast10YearsOfAmericanLifeHaveBeenUniquelyStupid),追溯了过去十年里社交媒体的进化史,及其对美国公众的负面影响。
在海特看来,2009-2011年左右的社交媒体,经历了从“善”到“恶”的分水岭式转变。其中一个很重要的标志,就是脸书采用了全新的设计,更改了在用户的主页上内容显示的排序方式:从按“时间”排序变成了按“喜好”排序。
2009年之前,以脸书为代表的新一代社交媒体,使用的都是“按时间先后排序”——你在主页上看到的内容(好友最新的动态,关注人的发帖)基本都按照一个非常简单的先后顺序排列,最新的帖子排在最前面。2009年,脸书给所有的帖子增加了“赞”(Like)的按钮,推特则进一步,增加了“转发”(Retweet)的功能。脸书迅速跟进,在“赞”的基础上,增加了“分享”(Share)的功能。
这些小小按钮的增加,赋予了社交媒体在某种程度上体察用户心理的超能力。脸书首当其冲地发现了“点赞”按钮产生的数据,经由算法的处理,能准确地预测哪些内容更容易迎合用户喜好,增加用户与平台互动的频率,从而把用户尽可能长时间地留在平台上。很快,以脸书为代表的新一代社交媒体全体转向,几乎毫无例外地一致采用了按用户的喜好——以“点赞”“分享”“转发”为基准进行量化——排列主页内容的方式。
站在2009-2011年转向之初的社交媒体用户们,起先并没有发现更改内容排序设计的威力。
脸书用户们最开始的困惑是,有些之前经常发帖的朋友,莫名其妙地从他们的主页上消失了。他们以为,也许是朋友把他屏蔽了——“我再未见过她贴任何东西!我一直以为我和那个人并不是那么亲近”。
紧接着,研究者们的大规模实验开始发现,什么样的帖子最容易收到用户的“点赞”“分享”“转发”呢?那些能够引发用户情感层面上的反应的,尤其是,能够引发对自己群体以外的那批人的愤怒的。这意味着,短平快、情绪激烈、容易激起愤怒的帖子在算法排序的时代里更占优势。长文,不引发情绪反应的、平缓的说理文,会逐渐从用户的主页被算法默默抹去。在美国的语境下,也同时意味着社交媒体上,保守派和自由派之间的裂痕由此日渐加大。
更为严重的是,各大自媒体运营商在接入体量日渐庞大的社交平台之后,也在自觉或不自觉地按照这一平台制定的规则行事。如果能把用户的“点赞”“分享”“转发”应用好,也就是,如果能有效地利用人类容易被情绪和愤怒左右的天性,你的帖子会更容易“火”,更容易被算法推荐,被更多人阅读和打赏,也就更容易转化为直接可观的利益收入。
当然,最可怕的是,这个看似简单的排序方式的更改,在不自觉地影响着人类在社交媒体上的行为。也就是说,一开始按人类喜好训练的排序算法,在日复一日的排序过程中和人类用户进一步互动,也在不知不觉中重新塑造着人类用户的喜好:你喜欢愤怒的帖子,我给你更多愤怒的帖子,直到愤怒的程度被重新定义。
2021年,耶鲁大学的心理学家威廉·布雷迪(WilliamBrady)的团队使用计算机软件收集并分析了来自7331名推特用户围绕一系列政治上极具争议的话题发表的1270万条推文。论文发现:“社交媒体的激励机制正在改变我们在线政治对话的基调……一些人甚至随着时间的推移学会了表达更多的愤怒,因为他们得到了社交媒体算法的正向反馈。”
在机器学习里,这种算法范式被广泛运用于各大社交媒体平台,在与大规模人类用户的互动里发扬光大,有个非常反讽的名字,叫做“强化学习”(ReinforcementLearning)。
海特在他那篇引发巨大反响的雄文里反思到,社交媒体的这些貌似微不足道的设计在过去的十年里重塑了美国人的生活,“我们迷失了方向,无法说同样的语言,也无法认识同样的真理。我们不仅彼此隔绝,也与过去隔绝。”(Wearedisoriented,unabletospeakthesamelanguageorrecognizethesametruth.Wearecutofffromoneanotherandfromthepast.)
经过激烈的辩论,斯蒂尔那篇论文得以面世。在论文的最后,斯蒂尔和作者们对他们设计的验证码和备受争议的“说服性设计”提出了三个反思性问题:
“首先,我们必须考虑哪些形式的‘说服性设计’、在何种场景下、是可以接受的?这意味着在商业场景下、政治场景下、健康场景下会有不同的考量。
其次,我们必须考虑披露问题。在道德上什么程度的披露是必要的?是否应该在法律层面上要求使用说服性设计的组织披露他们正在使用说服性设计?是否应该要求他们具体披露他们是如何使用的?
最后,是否应该使用说服性设计?我们认为,最后一个问题已经有了答案;说服性设计实际上已然是当代所有(人机交互)设计的核心,无法与之分割。说我们不使用说服性设计,相当于说我们对于一种设计是如何影响人类行为一无所知。”
参考文献:
1.Seering,J.,Fang,T.,Damasco,L.,Chen,M.C.,Sun,L.,IalwaysassumedthatIwasntreallythatcloseto[her]ReasoningaboutInvisibleAlgorithmsinNewsFeeds.InProceedingsofthe33rdannualACMconferenceonhumanfactorsincomputingsystems(pp.153-162).
4.Brady,W.J.,Wills,J.A.,Jost,J.T.,Tucker,J.A.,">5.Rathje,S.,VanBavel,J.J.,">6.Brady,W.J.,McLoughlin,K.,Doan,T.N.,">-----
作者沈虹,毕业于美国伊利诺伊大学香槟分校传播学系,现任职于美国卡内基梅隆大学。她用社会学的方法研究新兴科技。